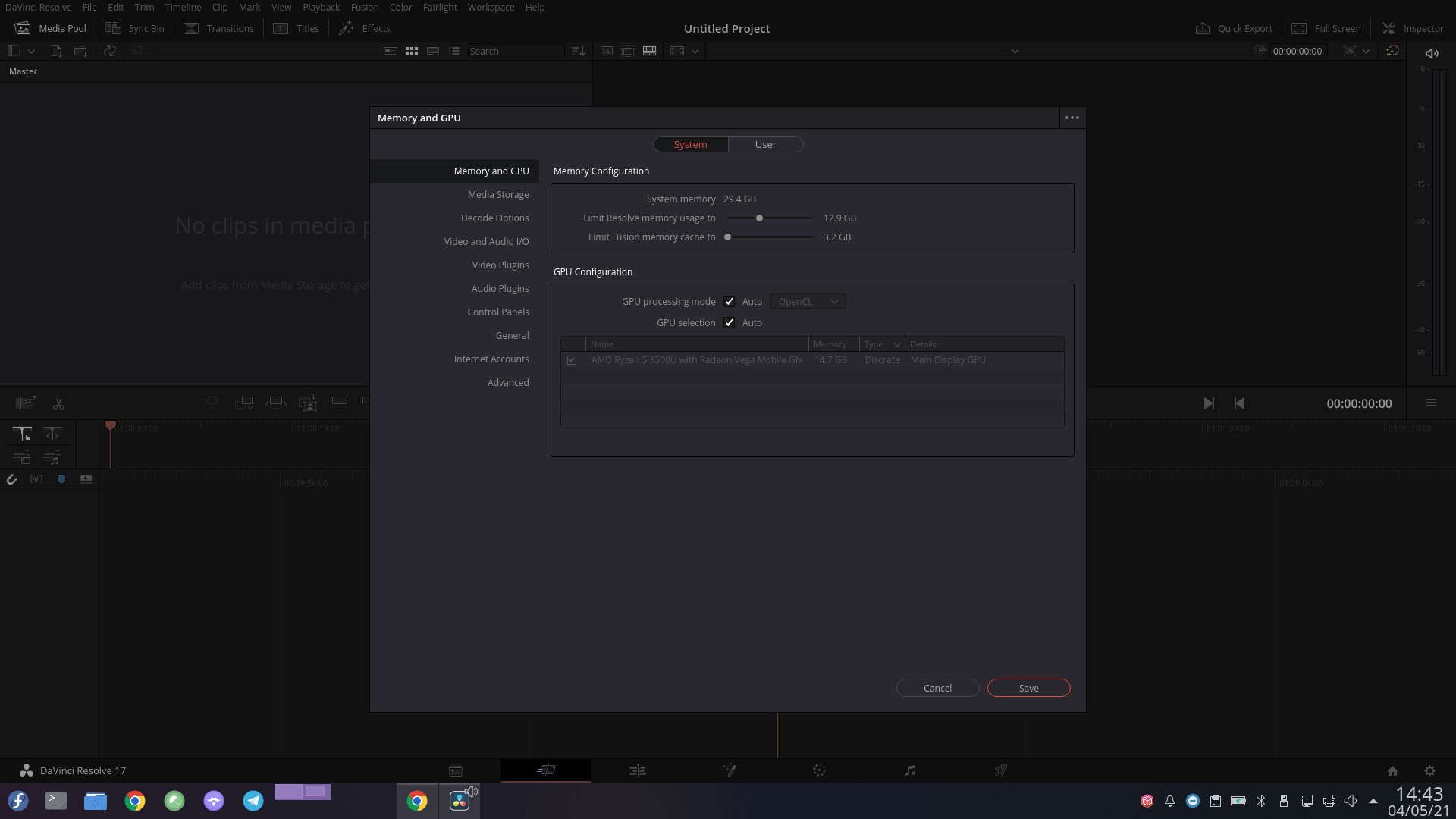
In questa guida spiegheremo come installare e configurare Da Vinci Resolve 17 su Fedora 34.
Innanzi tutto andiamo a scaricare i driver ROCM 2.5 di AMD.
Ora creiamo il file repo locale /etc/yum.repos.d/rocm.repo contenente le seguenti righe :
[ROCm]
name=ROCm
baseurl=http://repo.radeon.com/rocm/yum/2.5/
enabled=1
gpgcheck=0
E ora installiamo i pacchetti necessari per far funzionare OpenCL:
Se hai una scheda VEGA o più recente ( testato su AMD Ryzen 5 3500U with Radeon Vega 8 Mobile )
# Install prereqs for hcc
sudo dnf install npth-devel hsa-ext-rocr-dev rocm-utils
# force hcc installation
sudo dnf download hcc
sudo rpm -ifvh hcc-1.3.19212-Linux.rpm --nodeps
Installiamo i seguenti pacchetti: ( il risultato vi darà che è stato installato già precedentemente )
sudo dnf install rocm-clang-ocl rocm-opencl rocm-opencl-devel rocm-utils
Diamo il seguente comando:
/usr/bin/rocminfo
Output
ROCk module is loaded
Able to open /dev/kfd read-write
=====================
HSA System Attributes
=====================
Runtime Version: 1.1
System Timestamp Freq.: 1000.000000MHz
Sig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)
Machine Model: LARGE
System Endianness: LITTLE
==========
HSA Agents
==========
*******
Agent 1
*******
Name: AMD Ryzen 5 3500U with Radeon Vega Mobile Gfx
Uuid:
Marketing Name: AMD Ryzen 5 3500U with Radeon Vega Mobile Gfx
Vendor Name: CPU
Feature: None specified
Profile: FULL_PROFILE
Float Round Mode: NEAR
Max Queue Number: 0(0x0)
Queue Min Size: 0(0x0)
Queue Max Size: 0(0x0)
Queue Type: MULTI
Node: 0
Device Type: CPU
Cache Info:
L1: 32(0x20) KB
Chip ID: 5592(0x15d8)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 2100
BDFID: 768
Internal Node ID: 0
Compute Unit: 8
SIMDs per CU: 4
Shader Engines: 1
Shader Arrs. per Eng.: 1
WatchPts on Addr. Ranges:4
Features: None
Pool Info:
Pool 1
Segment: GLOBAL; FLAGS: KERNARG, FINE GRAINED
Size: 33554048(0x1fffe80) KB
Allocatable: TRUE
Alloc Granule: 4KB
Alloc Alignment: 4KB
Accessible by all: TRUE
ISA Info:
N/A
*******
Agent 2
*******
Name: gfx902
Uuid:
Marketing Name: AMD Ryzen 5 3500U with Radeon Vega Mobile Gfx
Vendor Name: AMD
Feature: KERNEL_DISPATCH
Profile: FULL_PROFILE
Float Round Mode: NEAR
Max Queue Number: 128(0x80)
Queue Min Size: 4096(0x1000)
Queue Max Size: 131072(0x20000)
Queue Type: MULTI
Node: 0
Device Type: GPU
Cache Info:
L1: 16(0x10) KB
Chip ID: 5592(0x15d8)
Cacheline Size: 64(0x40)
Max Clock Freq. (MHz): 1200
BDFID: 768
Internal Node ID: 0
Compute Unit: 11
SIMDs per CU: 4
Shader Engines: 1
Shader Arrs. per Eng.: 1
WatchPts on Addr. Ranges:4
Features: KERNEL_DISPATCH
Fast F16 Operation: FALSE
Wavefront Size: 64(0x40)
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Max Waves Per CU: 160(0xa0)
Max Work-item Per CU: 10240(0x2800)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
Max fbarriers/Workgrp: 32
Pool Info:
Pool 1
Segment: GROUP
Size: 64(0x40) KB
Allocatable: FALSE
Alloc Granule: 0KB
Alloc Alignment: 0KB
Accessible by all: FALSE
ISA Info:
ISA 1
Name: amdgcn-amd-amdhsa--gfx902+xnack
Machine Models: HSA_MACHINE_MODEL_LARGE
Profiles: HSA_PROFILE_BASE
Default Rounding Mode: NEAR
Default Rounding Mode: NEAR
Fast f16: TRUE
Workgroup Max Size: 1024(0x400)
Workgroup Max Size per Dimension:
x 1024(0x400)
y 1024(0x400)
z 1024(0x400)
Grid Max Size: 4294967295(0xffffffff)
Grid Max Size per Dimension:
x 4294967295(0xffffffff)
y 4294967295(0xffffffff)
z 4294967295(0xffffffff)
FBarrier Max Size: 32
*** Done ***
Controlliamo che clinfo funzioni correttamente:
/usr/bin/clinfo
Output
Number of platforms 1
Platform Name AMD Accelerated Parallel Processing
Platform Vendor Advanced Micro Devices, Inc.
Platform Version OpenCL 2.1 AMD-APP (2833.0)
Platform Profile FULL_PROFILE
Platform Extensions cl_khr_icd cl_amd_event_callback cl_amd_offline_devices
Platform Host timer resolution 1ns
Platform Extensions function suffix AMD
Platform Name AMD Accelerated Parallel Processing
Number of devices 1
Device Name gfx902-xnack
Device Vendor Advanced Micro Devices, Inc.
Device Vendor ID 0x1002
Device Version OpenCL 1.2
Driver Version 2833.0 (HSA1.1,LC)
Device OpenCL C Version OpenCL C 2.0
Device Type GPU
Device Board Name (AMD) AMD Ryzen 5 3500U with Radeon Vega Mobile Gfx
Device Topology (AMD) PCI-E, 03:00.0
Device Profile FULL_PROFILE
Device Available Yes
Compiler Available Yes
Linker Available Yes
Max compute units 11
SIMD per compute unit (AMD) 4
SIMD width (AMD) 16
SIMD instruction width (AMD) 1
Max clock frequency 1200MHz
Graphics IP (AMD) 9.2
Device Partition (core)
Max number of sub-devices 11
Supported partition types None
Supported affinity domains (n/a)
Max work item dimensions 3
Max work item sizes 1024x1024x1024
Max work group size 256
Preferred work group size (AMD) 256
Max work group size (AMD) 1024
Preferred work group size multiple 64
Wavefront width (AMD) 64
Preferred / native vector sizes
char 4 / 4
short 2 / 2
int 1 / 1
long 1 / 1
half 1 / 1 (cl_khr_fp16)
float 1 / 1
double 1 / 1 (cl_khr_fp64)
Half-precision Floating-point support (cl_khr_fp16)
Denormals No
Infinity and NANs No
Round to nearest No
Round to zero No
Round to infinity No
IEEE754-2008 fused multiply-add No
Support is emulated in software No
Single-precision Floating-point support (core)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Correctly-rounded divide and sqrt operations Yes
Double-precision Floating-point support (cl_khr_fp64)
Denormals Yes
Infinity and NANs Yes
Round to nearest Yes
Round to zero Yes
Round to infinity Yes
IEEE754-2008 fused multiply-add Yes
Support is emulated in software No
Address bits 64, Little-Endian
Global memory size 15776258048 (14.69GiB)
Global free memory (AMD) 15406502 (14.69GiB)
Global memory channels (AMD) 2
Global memory banks per channel (AMD) 4
Global memory bank width (AMD) 256 bytes
Error Correction support No
Max memory allocation 13409819340 (12.49GiB)
Unified memory for Host and Device Yes
Minimum alignment for any data type 128 bytes
Alignment of base address 1024 bits (128 bytes)
Global Memory cache type Read/Write
Global Memory cache size 16384 (16KiB)
Global Memory cache line size 64 bytes
Image support Yes
Max number of samplers per kernel 5592
Max size for 1D images from buffer 65536 pixels
Max 1D or 2D image array size 2048 images
Max 2D image size 16384x16384 pixels
Max 3D image size 2048x2048x2048 pixels
Max number of read image args 128
Max number of write image args 8
Local memory type Local
Local memory size 65536 (64KiB)
Local memory syze per CU (AMD) 65536 (64KiB)
Local memory banks (AMD) 32
Max number of constant args 8
Max constant buffer size 13409819340 (12.49GiB)
Preferred constant buffer size (AMD) 16384 (16KiB)
Max size of kernel argument 1024
Queue properties
Out-of-order execution No
Profiling Yes
Prefer user sync for interop Yes
Number of P2P devices (AMD) 0
P2P devices (AMD) (n/a)
Profiling timer resolution 1ns
Profiling timer offset since Epoch (AMD) 0ns (Thu Jan 1 01:00:00 1970)
Execution capabilities
Run OpenCL kernels Yes
Run native kernels No
Thread trace supported (AMD) No
Number of async queues (AMD) 8
Max real-time compute queues (AMD) 8
Max real-time compute units (AMD) 11
printf() buffer size 4194304 (4MiB)
Built-in kernels (n/a)
Device Extensions cl_khr_fp64 cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_int64_base_atomics cl_khr_int64_extended_atomics cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_fp16 cl_khr_gl_sharing cl_amd_device_attribute_query cl_amd_media_ops cl_amd_media_ops2 cl_khr_subgroups cl_khr_depth_images cl_amd_copy_buffer_p2p cl_amd_assembly_program
NULL platform behavior
clGetPlatformInfo(NULL, CL_PLATFORM_NAME, ...) No platform
clGetDeviceIDs(NULL, CL_DEVICE_TYPE_ALL, ...) No platform
clCreateContext(NULL, ...) [default] No platform
clCreateContext(NULL, ...) [other] Success [AMD]
clCreateContextFromType(NULL, CL_DEVICE_TYPE_DEFAULT) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx902-xnack
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CPU) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_GPU) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx902-xnack
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ACCELERATOR) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_CUSTOM) No devices found in platform
clCreateContextFromType(NULL, CL_DEVICE_TYPE_ALL) Success (1)
Platform Name AMD Accelerated Parallel Processing
Device Name gfx902-xnack
Ora eseguiamo Da Vinci da terminale ( ecco il risultato )